MySQL命令rebootClusterFromCompleteOutage重启集群注意事项
rebootClusterFromCompleteOutage()是MySQL Shell中的一个实用命令,用于在 InnoDB 集群遇到完全中断 (例如,当组复制在所有成员实例上停止时)后重新配置和恢复集群。这个命令允许你连接到集群中的一个 MySQL 实例,并使用该实例的元数据来恢复整个集群。
在MySQL Shell中使用rebootClusterFromCompleteOutage命令启动集群(MySQL InnoDB Cluster)
MySQL mysqlu01:7306 ssl JS > dba.rebootClusterFromCompleteOutage()
Restoring the Cluster 'Cluster_GSP' from complete outage...
Cluster instances: 'mysqlu01:7306' (OFFLINE), 'mysqlu02:7306' (OFFLINE), 'mysqlu03:7306' (OFFLINE)
Waiting for instances to apply pending received transactions...
Validating instance configuration at mysqlu01:7306...
This instance reports its own address as mysqlu01:7306
Instance configuration is suitable.
* Waiting for seed instance to become ONLINE...
mysqlu01:7306 was restored.
Validating instance configuration at mysqlu02:7306...
This instance reports its own address as mysqlu02:7306
Instance configuration is suitable.
Rejoining instance 'mysqlu02:7306' to cluster 'Cluster_GSP'...
Re-creating recovery account...
NOTE: User 'mysql_innodb_cluster_201'@'%' already existed at instance 'mysqlu01:7306'. It will be deleted and created again with a new password.
* Waiting for the Cluster to synchronize with the PRIMARY Cluster...
** Transactions replicated ############################################################ 100%
The instance 'mysqlu02:7306' was successfully rejoined to the cluster.
Validating instance configuration at mysqlu03:7306...
This instance reports its own address as mysqlu03:7306
Instance configuration is suitable.
Rejoining instance 'mysqlu03:7306' to cluster 'Cluster_GSP'...
Re-creating recovery account...
NOTE: User 'mysql_innodb_cluster_202'@'%' already existed at instance 'mysqlu01:7306'. It will be deleted and created again with a new password.
* Waiting for the Cluster to synchronize with the PRIMARY Cluster...
** Transactions replicated ############################################################ 100%
The instance 'mysqlu03:7306' was successfully rejoined to the cluster.
The Cluster was successfully rebooted.
<Cluster:Cluster_GSP>
MySQL mysqlu01:7306 ssl JS >
那么,关于命令rebootClusterFromCompleteOutage的一些知识点或注意事项,必须弄清楚,避免踩坑或稀里糊涂的。下面是一些简单总结,当前测试环境为MySQL 8.0.35,随着版本的变更,可能会有一些特性变化,请以实际情况为准。
1.确保集群的所有成员/节点在运行命令之前都已启动:在执行dba.rebootClusterFromCompleteOutage()命令之前,需要确保所有集群成员的MySQL实例都已启动并且可以访问。 如果无法访问任何集群成员,该命令将失败。如下所示:
情况1: 三个节点的MySQL服务都未启动的情况
MySQL JS > \c icadmin@mysqlu03:7306
Creating a session to 'icadmin@mysqlu03:7306'
MySQL Error 2003 (HY000): Can't connect to MySQL server on 'mysqlu03:7306' (111)
MySQL JS >
三个节点都没有启动时,MySQL Shell甚至都无法连接上。
情况2: 三个节点中,有一个或两个节点未启动情况
MySQL mysqlu01:7306 ssl JS > dba.rebootClusterFromCompleteOutage()
Restoring the Cluster 'Cluster_GSP' from complete outage...
Cluster instances: 'mysqlu01:7306' (OFFLINE), 'mysqlu02:7306' (UNREACHABLE), 'mysqlu03:7306' (UNREACHABLE)
WARNING: One or more instances of the Cluster could not be reached and cannot be rejoined nor ensured to be OFFLINE: 'mysqlu02:7306', 'mysqlu03:7306'. Cluster may diverge and become inconsistent unless all instances are either reachable or certain to be OFFLINE and not accepting new transactions. You may use the 'force' option to bypass this check and proceed anyway.
ERROR: Could not determine if Cluster is completely OFFLINE
Dba.rebootClusterFromCompleteOutage: Could not determine if Cluster is completely OFFLINE (RuntimeError)
MySQL mysqlu01:7306 ssl JS >
2.这种启动方式,它会自动找出GTID值最大的成员/节点作为MGR的引导节点吗?如果不能,是否需要mysql shell连接到集群中GTID最大的成员/节点,然后执行这个命令呢?
如下所示,集群中有三个节点mysqlu01,mysqlu02,mysqlu03
mysql> select * from performance_schema.replication_group_members order by member_host\G;
*************************** 1. row ***************************
CHANNEL_NAME: group_replication_applier
MEMBER_ID: 591280ce-bb5f-11ee-8862-00505697b437
MEMBER_HOST: mysqlu01
MEMBER_PORT: 7306
MEMBER_STATE: ONLINE
MEMBER_ROLE: PRIMARY
MEMBER_VERSION: 8.0.35
MEMBER_COMMUNICATION_STACK: MySQL
*************************** 2. row ***************************
CHANNEL_NAME: group_replication_applier
MEMBER_ID: 6ae7d68b-ba96-11ee-8092-005056971158
MEMBER_HOST: mysqlu02
MEMBER_PORT: 7306
MEMBER_STATE: ONLINE
MEMBER_ROLE: SECONDARY
MEMBER_VERSION: 8.0.35
MEMBER_COMMUNICATION_STACK: MySQL
*************************** 3. row ***************************
CHANNEL_NAME: group_replication_applier
MEMBER_ID: 4fc54bd5-bbf3-11ee-b588-0050569783ac
MEMBER_HOST: mysqlu03
MEMBER_PORT: 7306
MEMBER_STATE: ONLINE
MEMBER_ROLE: SECONDARY
MEMBER_VERSION: 8.0.35
MEMBER_COMMUNICATION_STACK: MySQL
3 rows in set (0.00 sec)
ERROR:
No query specified
mysql>
我们先用命令将节点mysqlu03的MySQL实例关闭
sudo systemctl stop mysqld.service
然后在mysqlu01中进行一些插入操作,人为模拟节点mysqlu01的GTID要大于mysqlu03
insert into test
select 1007, 'k1007' union all
select 1008, 'k1008';
mysql> insert into test
-> select 1007, 'k1007' union all
-> select 1008, 'k1008';
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
然后先后依次将mysqlu02,mysqlu01的MySQL服务关闭,然后启动这三个节点的MySQL服务,然后使用mysqlsh连接到mysqlu03上来启动
mysqlsh icadmin@mysqlu03:7306
或
mysqlsh icadmin@mysqlu03:7306 --log-level=DEBUG3
如下所示:
MySQL mysqlu03:7306 ssl JS > dba.rebootClusterFromCompleteOutage()
Restoring the Cluster 'Cluster_GSP' from complete outage...
Cluster instances: 'mysqlu01:7306' (OFFLINE), 'mysqlu02:7306' (OFFLINE), 'mysqlu03:7306' (OFFLINE)
Waiting for instances to apply pending received transactions...
Switching over to instance 'mysqlu01:7306' (which has the highest GTID set), to be used as seed.
NOTE: The instance 'mysqlu01:7306' is running auto-rejoin process, which will be cancelled.
Validating instance configuration at mysqlu01:7306...
This instance reports its own address as mysqlu01:7306
Instance configuration is suitable.
NOTE: Cancelling active GR auto-initialization at mysqlu01:7306
* Waiting for seed instance to become ONLINE...
mysqlu01:7306 was restored.
Validating instance configuration at mysqlu02:7306...
This instance reports its own address as mysqlu02:7306
Instance configuration is suitable.
Rejoining instance 'mysqlu02:7306' to cluster 'Cluster_GSP'...
Re-creating recovery account...
NOTE: User 'mysql_innodb_cluster_201'@'%' already existed at instance 'mysqlu01:7306'. It will be deleted and created again with a new password.
* Waiting for the Cluster to synchronize with the PRIMARY Cluster...
** Transactions replicated ############################################################ 100%
The instance 'mysqlu02:7306' was successfully rejoined to the cluster.
Validating instance configuration at mysqlu03:7306...
This instance reports its own address as mysqlu03:7306
Instance configuration is suitable.
Rejoining instance 'mysqlu03:7306' to cluster 'Cluster_GSP'...
Re-creating recovery account...
NOTE: User 'mysql_innodb_cluster_202'@'%' already existed at instance 'mysqlu01:7306'. It will be deleted and created again with a new password.
* Waiting for the Cluster to synchronize with the PRIMARY Cluster...
** Transactions replicated ############################################################ 100%
The instance 'mysqlu03:7306' was successfully rejoined to the cluster.
The Cluster was successfully rebooted.
<Cluster:Cluster_GSP>
MySQL mysqlu03:7306 ssl JS >
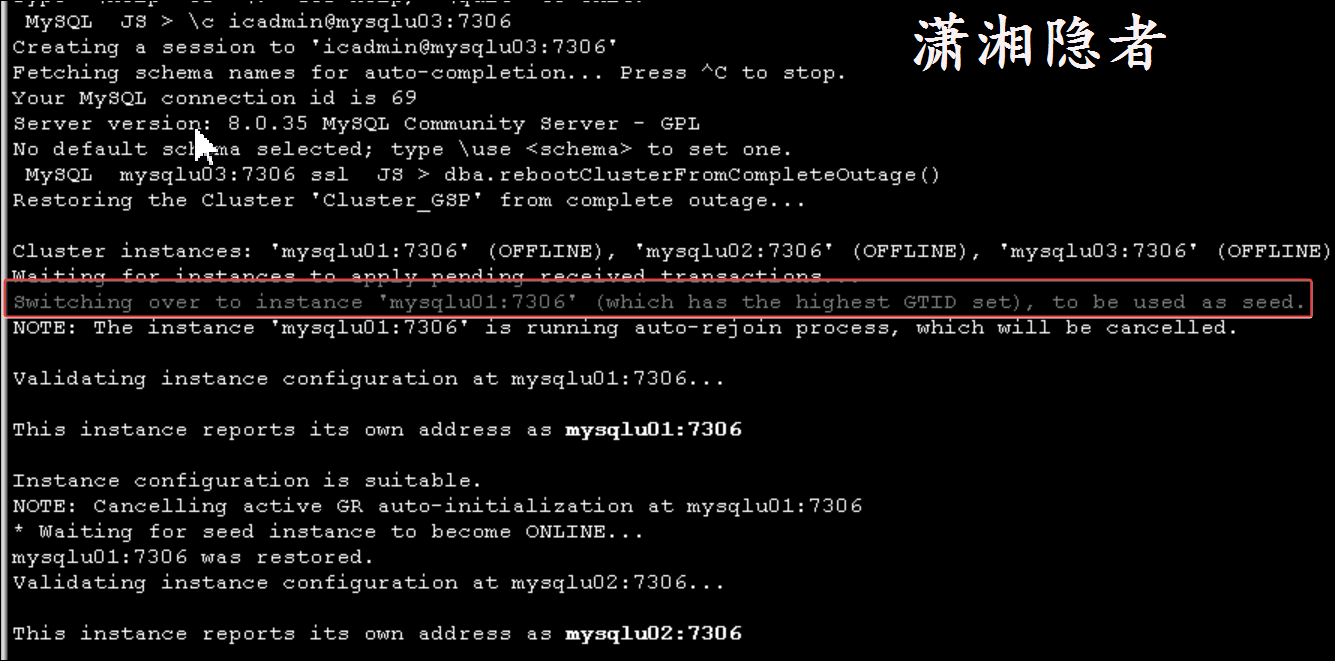
如上所示,从"Switching over to instance 'mysqlu01:7306' (which has the highest GTID set), to be used as seed."这个输出信息,我们可以清楚的 看到MySQL Shell中使用命令启动集群的时候,它会自动判断哪一个节点的GTID值最大,这个测试案例中,mysqlu01节点的GTID值最大,它就将mysqlu01作为 MGR的引导节点。所以,使用命令(dba.rebootClusterFromCompleteOutage())重启集群时,可以连接到集群的任一节点去启动集群。
注意:早期的版本,如果重新启动集群,需要连接到GTID最新的实例,也就是说必须连接到具有GTID超集的成员,即在中断之前应用了最多事务的实例。如果当前连接的实例的GTID不是最新(最大的值)的,则会报错,如下所示
Dba.rebootClusterFromCompleteOutage: The active session instance isn't the most updated
in comparison with the ONLINE instances of the Cluster's metadata.
Please use the most up to date instance: '***.***.***.***:3306'. (RuntimeError)
这个仅仅在早期版本中有这个问题。
另外,需要注意的是,如果集群中三个节点的GTID一致,如果集群关闭前主节点为mysqlu01,如果此时MySQL shell连接到mysqlu03去启动集群,此时mysqlu03会切换为主节点(PRIMARY),而mysqlu01会切换为从节点(SECOND)
3.使用force选项会忽略GTID集的分歧,并将所选成员作为主节点,丢弃未包含在所选成员GTID集中的任何事务。如果此过程失败,并且集群元数据已严重损坏, 你可能需要删除元数据并从头开始重新创建集群。这是一个危险的操作,因为它将删除所有集群元数据,并且不能撤销。 在实际操作中,应尽量避免使用force选项,因为它可能会引起数据不一致。只有在你完全了解可能产生的后果,并且没有其他选择时,才应考虑使用此选项。
如果你知道哪个节点具有最大的GTID值,但无法访问其他节点,可以使用force选项来强制重启集群。这将使用剩余可联系的成员来重启集群,即使某些成员当前无法访问
4.这种方式是集群中所有节点都关闭后使用,如果只是一个节点服务器重启或MySQL服务关闭后重启,并不能使用这种方式。
