字符编码发展史2 — ISO-8859-N
上一篇《字符编码发展史1 — ASCII和EASCII》我们讲解了字符编码的起源ASCII和EASCII。本篇我们将继续讲解字符编码的第二个发展阶段中的ISO 8859-N。
2.2. 第二个阶段 本地化
2.2.1. ANSI
计算机发明之初及后面很长一段时间,只用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。后来,随着个人计算机的发展和普及,美国这些生产计算机的企业(如IBM、惠普)希望把计算机卖到世界上更多的国家,其他的国家也希望能在自己的国家发展和应用计算机这个新技术,比如我们中国。
但是早期计算机使用ASCII编码只能满足英语国家和少数欧洲国家的需求,计算机要在全世界范围推广应用,就要解决各个国家语言编码的问题。各个国家、地区为了用计算机记录并显示自己的语言字符,都在ASCII编码方案的基础上,设计了各自的编码方案,于是就出现了很多适配不同地区语言的字符编码标准,如ISO 8859-N、GB2312、GBK、BIG5等,这些编码方案被国际标准化组织收纳并将其标准化。
通过多套编码方式来适配不同地区语言的过程,也叫字符编码的本地化。所有这些各个国家和地区所独立制定的既兼容ASCII又互相之间不兼容的字符编码,微软统称为ANSI编码。
ANSI其实有多个含义:
- ANSI: 全称是
American National Standards Institute,即 美国国家标准协会。它是一个非营利组织,负责协调和制定美国国家标准,并代表美国参与国际标准化活动。 - ANSI: 微软的ANSI代码页。
计算机的普及是伴随着Windows操作系统的发展的,Windows操作系统以其强大的图形化界面和优秀的人机交互迅速占领了个人计算机90%多的市场份额,占据了统治性地位。微软的Windows作为全球性的操作系统,为了能适配各个国家和地区的语言,制定了一套代码页,用于映射各个国家和地区的语言的字符编码,微软称之为ANSI代码页(即ANSI Code Page,简称ACP)。
2.2.2. ISO/IEC 8859-N
EASCII虽然增加了欧洲常用字符,但是能表达的字符依然太少,甚至说远远不够,比如希腊语的字母表。
为了解决这个问题,ISO/IEC 8859-N 字符集和编码方案便应运而生。
2.2.2.1. 什么是ISO/IEC 8859-N?
- ISO: 全称
International Organization for Standardization,即 国际标准化组织。它是一个全球性的非政府组织,负责制定和发布国际标准,以促进全球贸易和技术交流。 - IEC: 全称
International Electrotechnical Commission,即 国际电工委员会。它是一个全球性的非政府组织,负责制定和发布与电气、电子和相关技术领域的国际标准。 - ISO/IEC 8859: 是国际标准化组织(ISO)和国际电工委员会(IEC)制定的一组字符编码标准。
ISO/IEC 8859也经常简称ISO 8859,如``ISO 8859-1`(后面的内容均以简称的方式描述)。
ISO 8859字符编码与EASCII字符编码的设计思路一样:同样是采用单个字节(8位)的编码方式,在ASCII码的基础上,利用了ASCII没有用到的最高位(首位),将编码范围从原先ASCII码的0x00~0x7F(十进制为0~127),增加0x80~0xFF,扩展到了0x00~0xFF(十进制为0~255)。
与EASCII区别是:EASCII字符编码只包含了单个字符集(128个ASCII字符+128个扩展字符),而ISO 8859字符编码则包含一组字符集,每个字符集支持不同地区的语言。总共有15个子集,对应15种编码方式,从ISO 8859-1到ISO 8859-16,其中ISO 8859-12未定义,所以实际上是15个,这15个子集的区别如下:
| ISO 8859-n | 英文别名 | 表达的语种 | 中文解释 |
|---|---|---|---|
| ISO 8859-1 | Latin-1 | Western Europe | 西欧语言 |
| ISO 8859-2 | Latin-2 | Central Europe | 中欧语言 |
| ISO 8859-3 | Latin-3 | Southern Europe | 南欧语言。世界语也可用此字符集显示。 |
| ISO 8859-4 | Latin-4 | Baltic | 北欧语言 |
| ISO 8859-5 | Cyrillic | 斯拉夫语言 | |
| ISO 8859-6 | Arabic | 阿拉伯语 | |
| ISO 8859-7 | Greek | 希腊语 | |
| ISO 8859-8 | Hebrew | 希伯来语 | |
| ISO 8859-9 | [Latin-5 | Turkish | 土耳其语,它把Latin-1的冰岛语字母换走,加入土耳其语字母 |
| ISO 8859-10 | Latin-6 | Nordic | 北欧的日耳曼语支,用来代替Latin-4 |
| ISO 8859-11 | Thai | 泰国语,从泰国的 TIS620 标准字集演化而来 | |
| ISO 8859-13 | Latin-7 | Estonian | 爱沙尼亚语,或 Baltic Rim 波罗的语族 |
| ISO 8859-14 | Latin-8 | Celtic | 凯尔特语族 |
| ISO 8859-15 | Latin-9 | Western | 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。 |
| ISO 8859-16 | Latin-10 | Romanian | 罗马尼亚语,东南欧语言,主要供罗马尼亚语使用,并加入欧元符号。 |
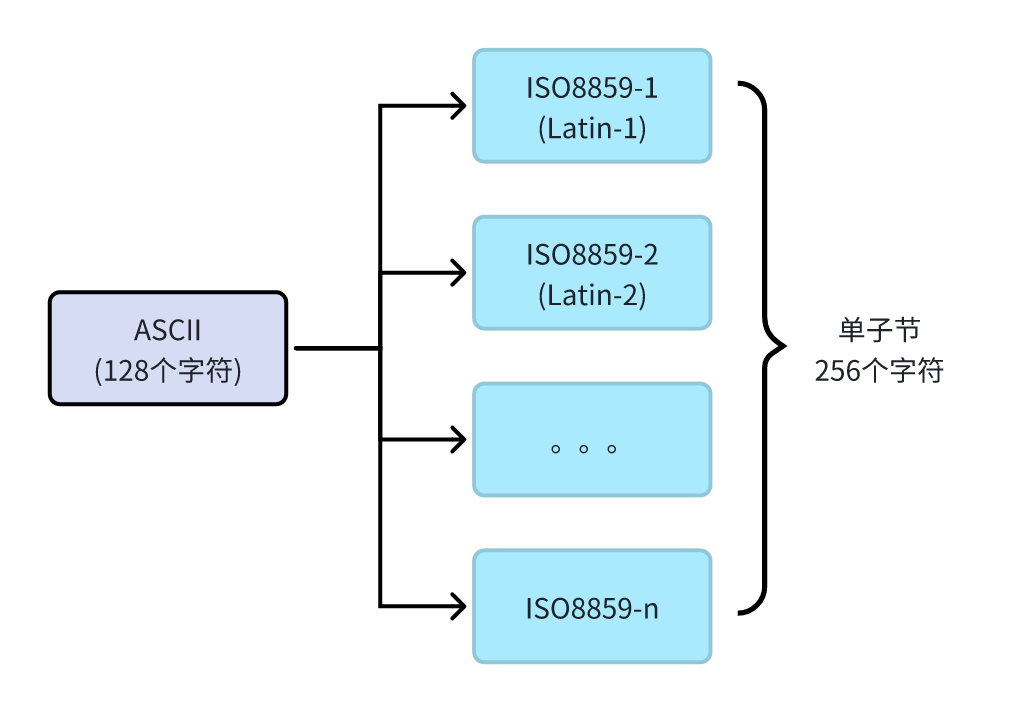
需要注意的是:
- 这15个字符集全部都兼容ASCII编码。
- 每一个字符集的补充扩展部分,都只实际使用了
0xA0~0xFF(十进制为160~255)这96个编码,而0x80~0x9F(十进制为128~159)这32个编码并未实际定义字符。
至此,ISO 8859-N系列编码,基本上能满足大部分(以拉丁字符为语系的)欧洲国家。
2.2.2.2. ISO 8859-1的编码表
我们可以看一下ISO-8859-1的编码表:
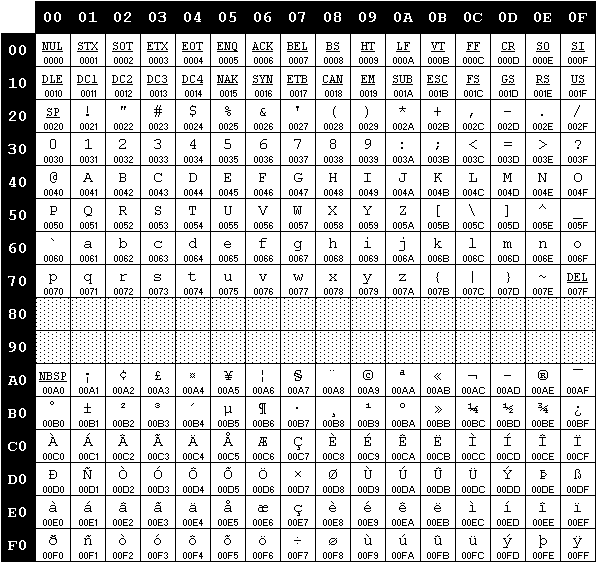
ISO-8859-1 编码表
未完待续…… 欲知后事如何,且看下回分解。
下回预告:字符编码发展史3 — GB2312/Big5/GBK/GB18030。
历史文章推荐:
大家好,我是陌尘。
IT从业10年+, 北漂过也深漂过,目前暂定居于杭州,未来不知还会飘向何方。
搞了8年C++,也干过2年前端;用Python写过书,也玩过一点PHP,未来还会折腾更多东西,不死不休。
感谢大家的关注,期待与你一起成长。
