JAVA基础之六-Stream(流)简介
我在别的篇幅已经说过:流这个东西偶尔可以用用,但我个人最大的学习动力(目前)仅仅是为了有助于阅读spring越发繁复的源码
本文主要介绍Stream接口(包括主要的方法)和相关的几个主要接口:Predicate、Consumer、Supplier
还有Collector接口,Collectors工具类。
由于网上已经有太多的文章介绍,所以,本文侧重点在于简单介绍基本的概念,并不会罗列所有的接口成员的说明(这些可以看javaDoc或者
官方的javaDoc)。
虽然主要说的是流,但也顺便说了一些其它东西:函数式接口之类
注:本文所相关代码和图是在J17环境下获得的。
一、重要接口、类及其定义
1.1、流直接相关接口/类
仅介绍部分:
- Stream
- Predicate
- Consumer
- Supplier
- xxxOperator
- xxxFunction
- Collector
- Collectors
Stream,Collector,Collectors是java.util.stream之下的,剩下的都是在java.util.function之下
1.Stream(普通接口)
流接口的类层次结构如下图:
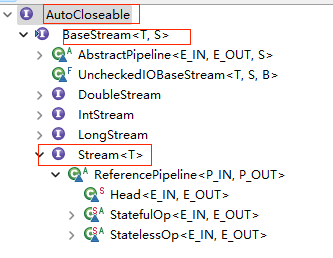
可以看到Stream继承自BaseStream,后者则继承了AutoCloseable。顺便提一句,并不是什么都可以自动关闭,如果是文件流需要自己关闭,Stream的javaDoc有提到。
此外,有可以看到,还有几个继承自BaseStream的其它Stream,包括DoubleStream,IntStream,LongStream,..
有点不太明白的是,为什么java17中没有提供其它可以聚集的数据类的Stream,例如为什么没有BigDecimalStream,BigIntStream? 有空再补充。
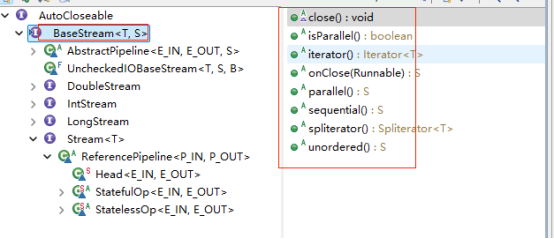
BaseStream重要定义了和计算不太相干的一些行为(并发、迭代等),如下图:
Stream自己则专注于计算/转换有关的,如下图:
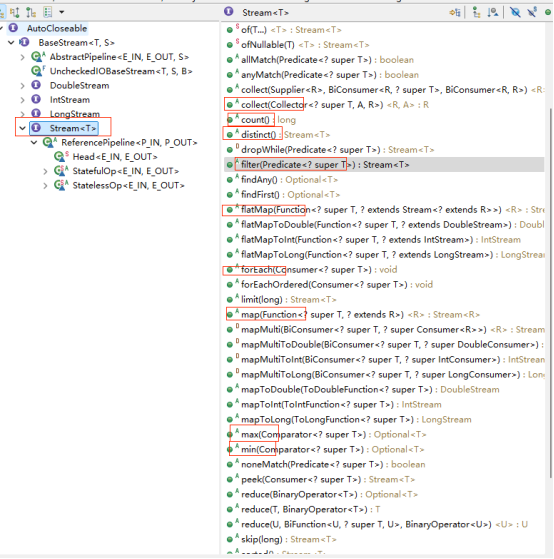
如上图,都是诸如min,max,count,distinct之类的熟悉字眼,还有份额不小的各种mapXXX。
基本上,需要流做的,或者善于让流做的事情,都定义好了。
2.Predicate(函数式接口)
Predicate ,中文有许多翻译:谓词、断言、表明、预测、断定等。
不过结合大量的方法定义,我觉得翻译为“断定”可能更好理解,一个根据输入确定是否真伪的对象,好似人类的推官、断事官、审判员。
为了便于行文,后面都会写成Predicate或者断定。
这个断定接口定义了几个重要的方法:
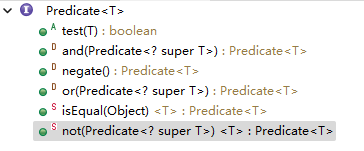
可以看到,只有一个test是需要实现的,其它几个都是默认的或者是静态的。
这个接口要实现类返回一个布尔值,断定传入的参数/内容是否合乎某个标准。
3.Consumer(函数式接口)
Consumer-消费者,这个翻译没有异议。
所以消费者接口比较简单,就两个方法:
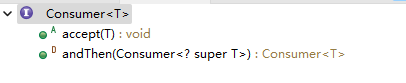
其中的accept不返回任何东西,重要的是andThen,可以让人一直andThen下去,只要没有异常。
也就是说,消费者可以一直消费,只要愿意。
4.Supplier(函数式接口)
和消费者对应的是供应者。
和消费者不同的是,供应者只有一个get方法。
所以供应者提供了之后,就只能等着,然后消费者可以一直消费。
5.各种Operator
Operator有的地方翻译为操作符,有的地方翻译为操作数。
结合已有的各种xxxOperator:BinaryOperator、DoubleUnaryOperator、UnaryOperator..
翻译为"操作者",以应合提供者、消费者。
各种操作者都是有返回的。 JCP大概把难于清晰界定其作用的各种函数式接口定义为操作者。
6..Bi,Binary是什么鬼?
Bi
在java.util.function下带有许多Bi开头的,例如BiFunction,BiConsumer,BiPredicate,xxxBixxx。
Bi是一个前缀,源自拉丁bis,表示两个、两次、两倍,总之就是2xxx。
所以带Bi开头的都是指有2个参数,而不带Bi的对应的都是一个参数为主(目前)。看看Predicate,BiPredicate就明白了:
@FunctionalInterface public interface BiPredicate<T, U> { boolean test(T t, U u); } @FunctionalInterface public interface Predicate<T> { boolean test(T t); }
注:为了节省篇幅,没有复制完整的源码和注释。
可以看到,Predicate带一个参数,BiPredicate有2个参数。
Jcp定义了不少Bixxx,大概是因为两个参数的场景也不少,否则为什么不定义三个,四个,...n个的Predicate等接口?
为了便于交流,我有的时候称呼Bixxx之类的函数为双参函数/方法,避免有些同事不知道这是什么玩意。
Binary
一般想到的是二进制,不过在这里Binary兼有Bi和一致的含义,合起来就是2个参数,且参数类型一致(包括返回也是一样)。
拿非常典型的java.util.function.BinaryOperator<T>看下:
public interface BinaryOperator<T> extends BiFunction<T,T,T>
BiFunciton的定义(局部):
@FunctionalInterface public interface BiFunction<T, U, R> { R apply(T t, U u); }
BiFunction必然是两个参数,但它不要求三个参数一致,而BinaryOperator则要求一致。
所以,这里Binary可以理解为三参一致,即两个入参和一个出参(返回值)一致,或者是两个入仓和返回值一致。
按照这个思维,其实JCP等可以考虑把这个命名为:triple
7.Collector(常规接口)
收集者 public interface Collector<T, A, R>
这是一个比较奇怪的接口,这是因为除了两个工具类的函数(of),其它的公共抽象方法的命名有背常规。
一般而言,方法的命名规范为:动词、动词+名词、形容词
例如 do(),doSomething(),isFinished()
但这里都是名词:supplier、accumulator、combiner、finisher、characteristics。
分别表示提供者、累积者、合并者、完成者、特征(注意,这里是一个集合)
Collector也提供了两个公共静态函数of,用于返回一个新的Collector实现。
在of函数中,其实即使使用Collectors.CollectorImpl 来实现。
所以,如果不想开发新的Collector实现,基本上用Collectors或者Collect.of即可,但本质上都是用Collectors.CollectorImpl
这也应该是JCP所期望的吧!
8.Collectors(实现Collector接口为主的工具类)
这个类非常有用。
当我们使用流处理的时候,常常会有转换的需要。当转换完成后需要输出另外一个格式的时候,就需要使用到收集器。
Collectors就是一个收集器集合,包含了各种各种的收集函数,实现诸如分组、转换(目标是list,map等)等操作
收集器集合中所有的公共方法方法返回的都是收集者(Collector)类型。
当我们查看源码,可以发现一个非常重要的地方:凡是返回Collector的public static 方法,最后都会调用:
return new CollectorImpl<>(supplier, accumulator, merger, finisher, characteristics);
CollectorImpl是Collector接口的实现,属于私有静态类(由于Collectors是final导致的)
java这些写的意图应该是这样的:你们不要费心(包括继承,扩展等等),就用Collectors的具体方法即可.
以常用toList()为例:
public static <T> Collector<T, ?, List<T>> toList() { return new CollectorImpl<>(ArrayList::new, List::add, (left, right) -> { left.addAll(right); return left; }, CH_ID); }
Collector类型的返回,可以被实现了Stream.collect利用,从而完成输出。
Stream的实现有很多,如前,最常见的是java.util.stream.ReferencePipeline<P_IN, P_OUT>
对于一般的工程师而言,想要Collect,可以这么做:
1.利用Collector.of构建一个,或者利用Colelctors的现货
2.把构建好的Collector当做入参,塞给Stream.collect方法.
3.完成
两个名词
mutable-可变的
immutable-不可变的
阅读stream代码的时候,需要格外注意哪些参数是可变的,还是不可变的。
特别注意:对于管道操作、流操作,要求部分参数不可变是一个很常见的要求。
1.2、java对其它接口/类的改造
主要是对集合类型的改造(从1.8开发)。
1.2.1、Colletion改造
集合类型的基类Collection新增了几个接口(J8开始):
default Stream<E> parallelStream() { return StreamSupport.stream(spliterator(), true); } @Override default Spliterator<E> spliterator() { return Spliterators.spliterator(this, 0); } default Stream<E> stream() { return StreamSupport.stream(spliterator(), false); }
上面这个Splitrator(可分割迭代器) 主要也是为了服务于并行流。如果不是采用并行流,那么也会用到,只不过不执行分隔而已(存疑)。
JCP都提供了默认实现,并为这些默认实现提供了对应的静态工具类:StreamSupport,Spliterators.
如此,所有Collection的实现类都可以使用steam,parallelStream方法。
1.2.2、Map?
Map中没有和流有关的改造,主要是对函数式编程的改造,或者具体一点就是增加了郎打的实现。
default void forEach(BiConsumer<? super K, ? super V> action) default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) default V computeIfAbsent(K key,Function<? super K, ? extends V> mappingFunction) default V computeIfPresent(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) default V compute(K key,BiFunction<? super K, ? super V, ? extends V> remappingFunction) default V merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction)
注意:这几个都是默认函数,意味着子子孙孙类都不用特别覆盖,不用特别实现,可以直接用了。
这是是顺便提一下,和流没有什么直接关系,但他们都和函数式接口相关。
1.3、java提供的一些新工具类
这个比较多,包括前面提到的Collectors,StreamSupport,Spliterators等,更多的可以看java.util.stream,java.util.function,java.util下有关代码。
二、简单的Collector示例
基本上,要做流处理,工程师大部分情况下都可以不要写多余代码就能实现,这是因为这些操作有共性,JAVA
提供了基本的实现,这些实现又基本覆盖了可以想象的地方。
如前,新增的工具类和对现有Collection的改造,使得工程师基本只要学习郎打表达式写法、工具类的使用,即可完成流操作。
在很大部分情况下,其实就是简化为对郎打语法、Collectors的学习-掌握了结果,基本在想用的时候就能用起来。
要实现Stream是如何完成Collect等,可以看Stream的标准实现类:java.util.stream.ReferencePipeline<P_IN, P_OUT>
示例-模仿java.util.stream.Collectors.CollectorImpl实现toList
public class ChineseArticles { private static List<ArticleRecord> ARTICLES; static { ARTICLES=new ArrayList<>(); ARTICLES.add(new ArticleRecord("唐","李白","侠客行",""" 十步杀一人 千里不留行 事了拂衣去 深藏身与名 """)); ARTICLES.add(new ArticleRecord("唐","李贺","马诗","大漠沙如雪")); } @SuppressWarnings("rawtypes") public static ArrayList createArrayList() { return new ArrayList(); } public static void add(ArrayList<ArticleRecord> t,ArticleRecord item) { t.add(item); } @SuppressWarnings({ "unchecked", "rawtypes" }) public static void main(String[] args) { List<ArticleRecord> list = getStream().collect(Collectors.toList()); System.out.println(list.toString()); Collector co = new ArticleCollector( ChineseArticles::createArrayList,// 供应者,类型参数是 ArrayList<ArticleRecord> ChineseArticles::add, // 聚集着,双参数,分别是 ArrayList<ArticleRecord>,ArticleRecord null, // 合并者,双参数,可以不要 null // 完成者- 在非并行的情况下,可以不要 ); Stream<ArticleRecord> articleRecordStream = getStream(); List<ArticleRecord> listUdf = (List<ArticleRecord>) articleRecordStream.collect(co); System.out.println(listUdf); } private static Stream<ArticleRecord> getStream() { return ARTICLES.stream().filter(article -> { return article.getDynasty().equals("唐") && article.getAuthor().equals("李贺"); }); } }
在这个非常简单的例子中,中间步骤是一个 filter,收尾操作是一个collect。
fitler接受Predicate的接口实现,由于Predicate是函数式接口,所以可以用郎打的方式写 :
article->{return article.getDynasty().equals("唐") && article.getAuthor().equals("李贺");}
无需单独定义一个Predicate实现类。
ArticleCollector是完全模仿CollectorImpl创建的一个Collectors.toList实现。
只不过属性characteristics=[Characteristics.IDENTITY_FINISH]
也可以直接利用Collector的静态方法来返回,不必要大费周章:
Collector.of(ChineseArticles::createArrayList, ChineseArticles::add, null, null, new Characteristics[] {Characteristics.IDENTITY_FINISH})
三、小结
1.java已经提供了比较完善的函数处理有关类和接口,理论上能够满足绝大部分的流处理场景
2.大部分时候,工程师只需要注意阅读Collectors,Stream,ReferencePipeline的代码,即可大体了解流是如何操作的
3.不鼓励工程师耗费大量的时间去阅读Stream的实现代码,比较复杂,对于一般的CRUD没有太大帮助。不过如果是为了提升专业技能还是有一定帮助的。
4.要熟练编写函数式代码,需要掌握函数式接口的几种实现方式 ,具体可见 JAVA基础之四-函数式接口和流的简介
或者JAVA基础之五-函数式接口的实现 (后面这个更全一些)